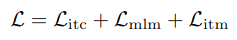
ALBEF
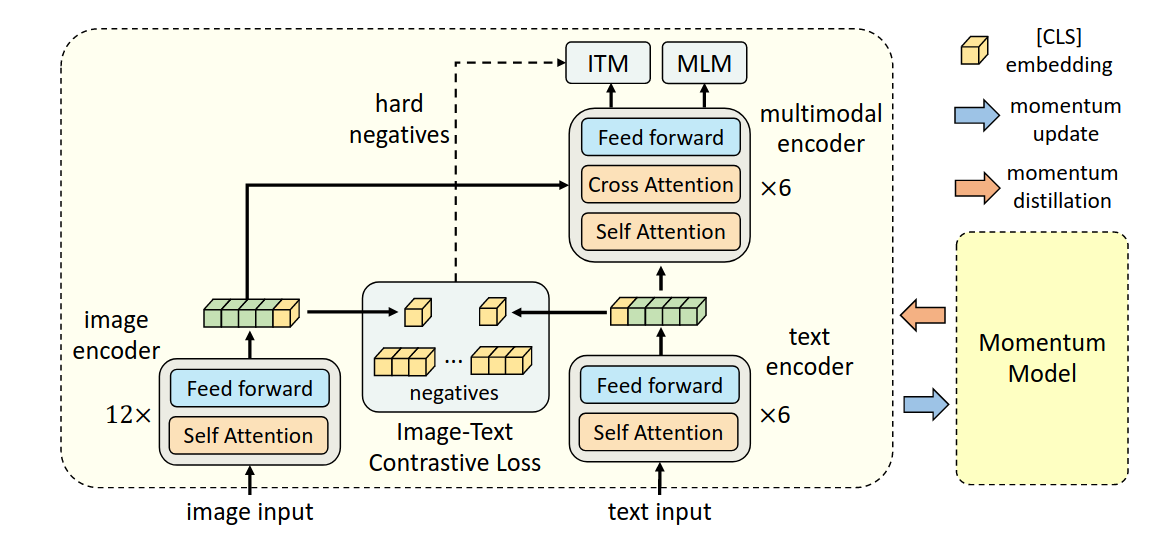
Text Encoder
使用的backbone是BERT(通过MLM训练)
该研究认为,image encoder的模型大小应该大于text encoder,所以在text encoder这里,只使用六层self attention来提取特征,剩余六层cross attention用于multi-modal encoder。
ITC Loss & Momentum
参考Moco [[Moco- Momentum Contrast for Unsupervised Visual Representation Learning]]
Improve Noisy Web Data
见[[BLIP]],是沿用的工作
Loss